
Apache Kafka – podstawy
Apache Kafka to system do przesyłania i przetwarzania danych w czasie rzeczywistym. Jest używany przez największe firmy technologiczne na świecie, ponieważ pozwala na niezawodne, szybkie i skalowalne przetwarzanie wiadomości.
W tym artykule wyjaśnię Kafkę w sposób klarowny i prosty, ale jednocześnie pełny i precyzyjny. Jeśli nigdy wcześniej nie pracowałeś z Kafką – zrozumiesz. Jeśli masz doświadczenie – mam nadzieję, że odkryjesz coś nowego.
1. Struktura Danych: Topic, Partycja, Offset
Topic – kanał do wymiany wiadomości
Topic to podstawowa jednostka organizacyjna w Kafce. Można go porównać do tabeli w bazie danych lub kanału komunikacyjnego – to miejsce, do którego producenci wysyłają wiadomości, a konsumenci je pobierają.
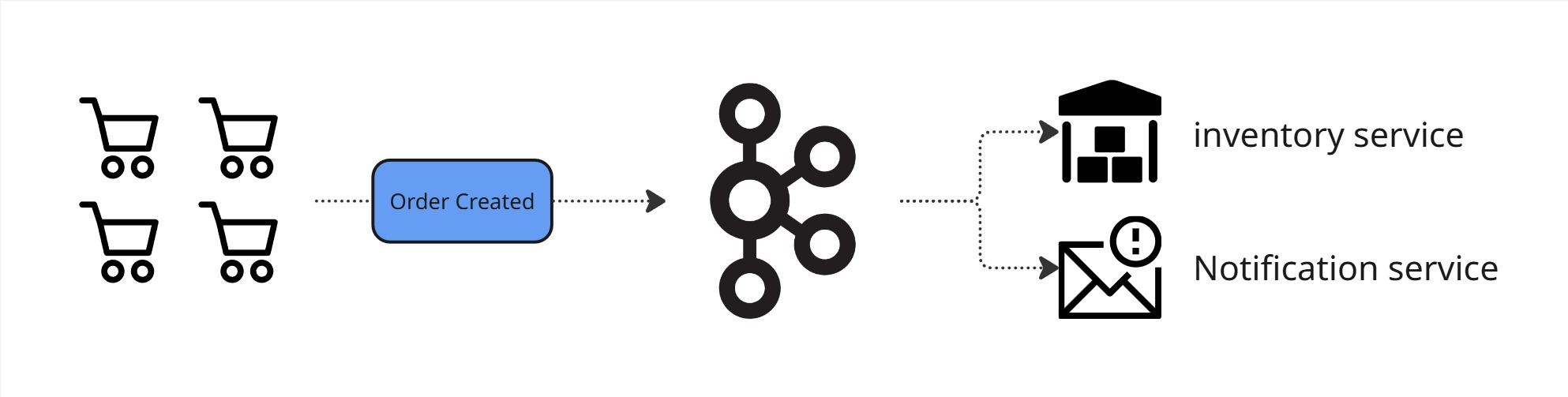
Cechy topicu:
- Możesz mieć nieskończoną liczbę topiców.
- Każdy topic ma unikalną nazwę.
- W topicu można przechowywać różne typy danych (np. JSON, Avro, binarne strumienie).
- Kafka traktuje wiadomości jako immutable – nie można ich edytować ani usuwać (chyba że ustalisz politykę retencji).
- Nie ma globalnej kolejności wiadomości – kolejność jest zachowana tylko w obrębie jednej partycji topicu.
Partycje – sposób na skalowanie
Topic w Kafce jest podzielony na partycje. To pozwala na równoległe przetwarzanie danych przez wielu konsumentów i zwiększa wydajność.
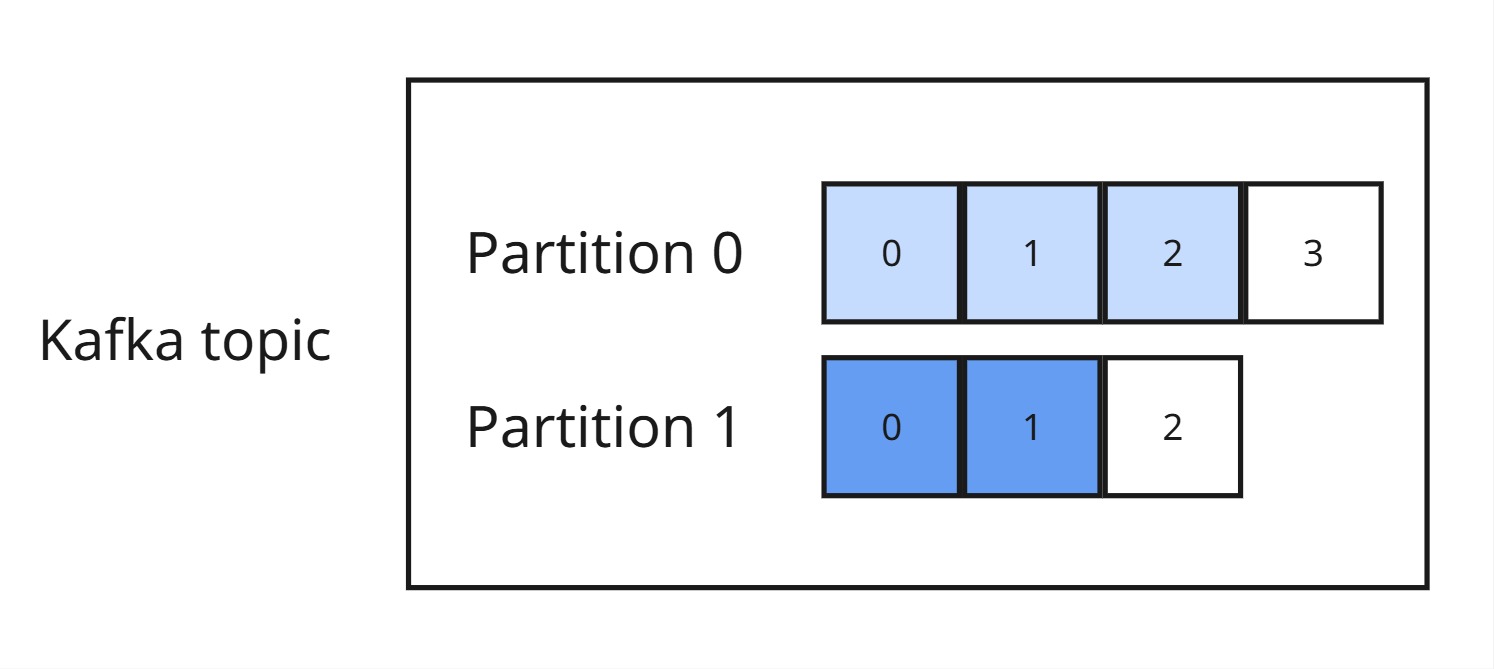
Jak działają partycje?
- Każda partycja ma swój własny zbiór wiadomości i działa jak niezależny mini-topic.
- Wiadomości w partycji są uporządkowane w kolejności ich dodania – Kafka gwarantuje, że zostaną odczytane w tej samej kolejności.
- Więcej partycji = większa skalowalność – można obsługiwać wielu konsumentów naraz.
Offset – numer ID wiadomości
Każda wiadomość w partycji ma swój unikalny numer, czyli offset. Offset pozwala śledzić, które wiadomości zostały już przetworzone.
- Offsety są lokalne dla partycji – Kafka nie numeruje wiadomości globalnie.
- Offsety są przechowywane w Kafka w specjalnym topicu (__consumer_offsets).
- Konsumenci mogą ręcznie lub automatycznie przesuwać offsety – to klucz do kontroli nad przetwarzaniem danych.
2. Wiadomość w Kafce
Wiadomość w Kafce składa się z kilku kluczowych elementów:
- Key (klucz) – opcjonalny identyfikator, który Kafka używa do przypisania wiadomości do partycji. Jeśli jest ustawiony, wiadomości z tym samym kluczem zawsze trafią do tej samej partycji.
- Value (wartość) – właściwa treść wiadomości. Może to być tekst, JSON, Avro, binarne dane – cokolwiek, co jest serializowane do zapisu.
- Timestamp (znacznik czasu) – informacja o tym, kiedy wiadomość została wysłana. Może pochodzić od producenta lub być nadana przez brokera.
- Headers (nagłówki) – dodatkowe metadane, które można przekazać w wiadomości. Mogą zawierać np. informacje o wersji wiadomości lub kontekście.
- Offset – unikalny numer w partycji, który pozwala konsumentowi śledzić, które wiadomości zostały już przetworzone.
Przykładowa wiadomość w formacie JSON:
{
"key": "user-123",
"value": "{"action": "login", "timestamp": 1714838293000}",
"timestamp": 1714838293000,
"headers": {"version": "1.0"},
"offset": 4523
}
Wiadomości w Kafce są immutable, co oznacza, że po ich zapisaniu nie można ich edytować ani usuwać (chyba że skorzystamy z konfiguracji retencji lub kompaktowania logów).
3. Produkowanie wiadomości
Producent – czyli kto wysyła dane?
Producent (Producer) to aplikacja, która wysyła wiadomości do topicu w Kafce. Jest odpowiedzialny za dostarczanie danych, ale równie istotne jest, do której partycji wiadomość zostanie przypisana. Kafka musi to określić, aby zachować spójność i wydajność systemu.
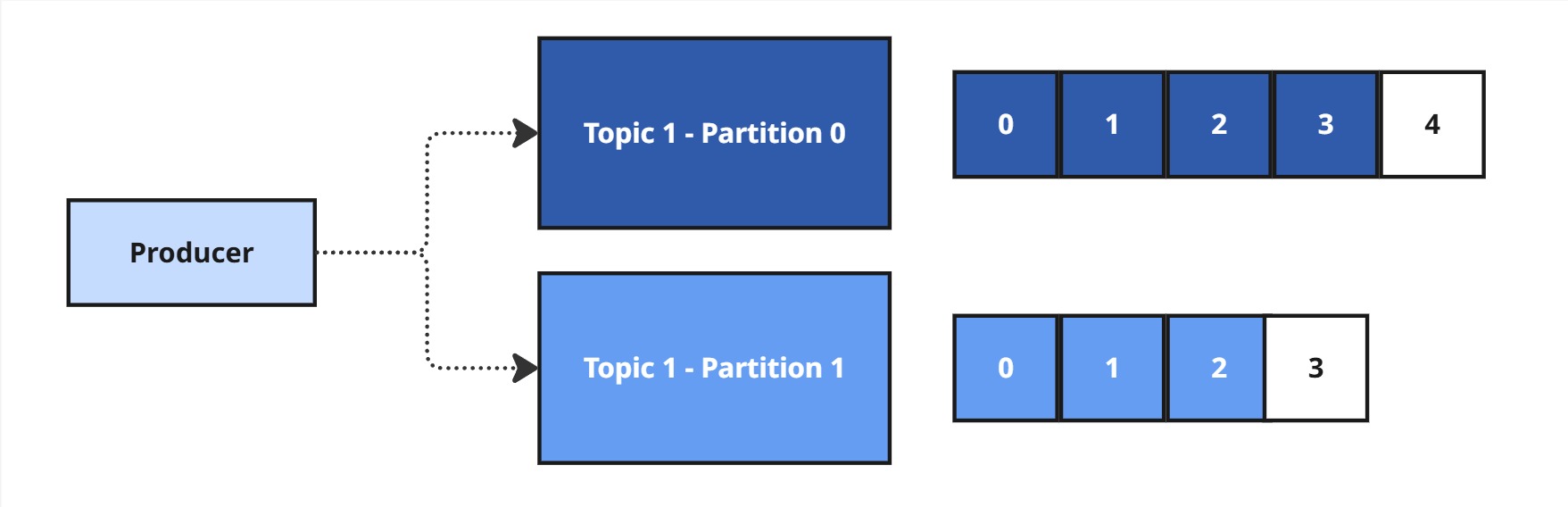
Jak Kafka wybiera partycję dla wiadomości?
Kafka stosuje dwa główne mechanizmy przypisywania wiadomości do partycji:
- Brak klucza (key = null) – Kafka stosuje round-robin, czyli wysyła wiadomości naprzemiennie do dostępnych partycji, co zapewnia równomierne rozłożenie obciążenia.
- Klucz (key ≠ null) – Kafka używa funkcji haszującej, aby przypisać wiadomość do konkretnej partycji:
int partition = Math.abs(key.hashCode()) % liczbaPartycji;Dzięki temu wiadomości z tym samym kluczem zawsze trafią do tej samej partycji. To kluczowe dla aplikacji, które wymagają zachowania kolejności wiadomości (np. przetwarzanie zdarzeń użytkownika czy transakcje finansowe).
4. Wyzwania przy produkowaniu wiadomości
W idealnym świecie liczba partycji nigdy by się nie zmieniała, ale rzeczywistość bywa bardziej skomplikowana. Co się stanie, jeśli dodamy nowe partycje? Standardowy mechanizm przypisywania wiadomości (hashCode() % liczbaPartycji) może sprawić, że te same klucze trafią do innych partycji, co zaburzy kolejność wiadomości. Jak temu zapobiec?
1. Statyczna liczba partycji
Najprostsze rozwiązanie – z góry ustalamy liczbę partycji i nigdy jej nie zmieniamy.
Zalety:
- Gwarantuje, że wiadomości o tym samym kluczu zawsze trafią do tej samej partycji.
- Brak problemów z redystrybucją kluczy.
Wady:
- Brak elastyczności – jeśli ruch rośnie, nie możemy dodać nowych partycji.
- Ryzyko nierównomiernego obciążenia partycji.
Kiedy używać:
- W systemach o przewidywalnym ruchu, gdzie kolejność jest krytyczna (np. transakcje finansowe).
2. Konsystentne haszowanie
Mechanizm, który zmniejsza wpływ zmiany liczby partycji na przypisanie kluczy.
Zalety:
- Nie przenosi wszystkich kluczy do innych partycji po zmianie liczby partycji – zmienia się tylko część.
- Dobre dla systemów, które muszą rosnąć dynamicznie.
Wady:
- Większa złożoność implementacyjna.
- Nie daje 100% gwarancji zachowania kolejności.
Kiedy używać:
- Gdy częste skalowanie jest konieczne, a częściowa utrata kolejności jest akceptowalna.
3. Migracja na nowy topic (Blue-Green Deployment)
Najbezpieczniejsza metoda w systemach wymagających utrzymania kolejności wiadomości, gdy trzeba zmienić liczbę partycji.
Jak to działa?
-
- Tworzymy nowy topic (
topic-v2) z nową liczbą partycji. - Producent zaczyna wysyłać wiadomości do obu topiców (
topic-v1itopic-v2). - Konsumenci odczytują oba topiki, ale priorytetowo
topic-v1. - Po określonym czasie (np. gdy
topic-v1zostanie opróżniony) przepinamy konsumentów natopic-v2. - Usuwamy stary topic (
topic-v1), gdy nie jest już potrzebny.
- Tworzymy nowy topic (
Zalety:
-
- 100% gwarancja zachowania kolejności wiadomości.
- Brak problemów ze zmianą liczby partycji w locie.
- Bezpieczna, stopniowa migracja.
Wady:
-
- Podwójne wysyłanie wiadomości przez pewien czas.
- Wymaga synchronizacji między producentami/konsumentami.
Kiedy używać:
- W systemach krytycznych (np. fintech, healthcare).
4. Partycjonowanie ręczne
Ręczne przypisywanie kluczy do partycji (np. przez producenta).
Zalety:
-
- Pełna kontrola nad dystrybucją.
- Brak niespodzianek przy skalowaniu.
Wady:
-
- Ryzyko nierównowagi obciążenia.
- Trudne do zarządzania przy dużych skalach.
Kiedy używać:
- Gdy klucze mają ścisłe wymagania lokalizacji (np. dane geograficzne).
5. Jak działa konsumpcja wiadomości w Apache Kafka?
Apache Kafka to system kolejkowania wiadomości oparty na partycjach i konsumentach, który zapewnia elastyczność w przetwarzaniu danych w czasie rzeczywistym. Zanim jednak zagłębimy się w mechanizmy grup konsumenckich, warto zrozumieć modele dostarczania wiadomości, które determinują sposób, w jaki Kafka dba o niezawodność, duplikację i wydajność.
5.1. Modele dostarczania wiadomości i strategie commitowania offsetów
Apache Kafka to system przetwarzania strumieni danych, który daje dużą elastyczność w dostarczaniu wiadomości. Aby w pełni zrozumieć, jakie gwarancje daje Kafka, musisz znać dwa kluczowe pojęcia:
-
Modele dostarczania wiadomości – czyli jakie są gwarancje, że wiadomość zostanie dostarczona i przetworzona.
-
Strategie commitowania offsetów – czyli kiedy Kafka uznaje, że wiadomość została przetworzona.
To nie są tożsame pojęcia, ale strategie commitowania offsetów determinują, który model dostarczania osiągasz w praktyce.
Modele dostarczania wiadomości (Delivery Semantics)
Kafka oferuje trzy poziomy gwarancji dostarczania wiadomości. Każdy z nich definiuje kompromis między wydajnością, prostotą, a niezawodnością:
1. At most once – wiadomość może zostać utracona
Najszybszy, ale najmniej bezpieczny model.
-
-
Jak działa: Konsument zatwierdza offset przed przetworzeniem wiadomości.
-
Zaleta: Bardzo szybkie przetwarzanie.
-
Wyzwania: Możliwa utrata danych – jeśli aplikacja padnie po commitcie, ale przed przetworzeniem.
-
Kiedy stosować: Niekrytyczne dane, np. logi, monitoring, metryki.
- Zwykle osiągany przez
enable.auto.commit=true.
-
2. At least once – wiadomość może być dostarczona więcej niż raz
Najczęściej używany model, zapewniający brak utraty danych.
-
Jak działa: Konsument przetwarza wiadomość, a dopiero potem commit’uje offset.
-
Zaleta: Żadna wiadomość nie zginie.
-
Wyzwania: Możliwe duplikaty – wymagane operacje idempotentne.
-
Kiedy stosować: Większość systemów biznesowych, np. transakcje, synchronizacje.
- Osiągany przez commitowanie offsetów po przetworzeniu wiadomości.
3. Exactly once – wiadomość przetworzona dokładnie raz
Złoty standard niezawodności.
-
Jak działa: Kafka i konsument używają transakcji i synchronizacji offsetów.
-
Zaleta: brak duplikatów i brak utraconych wiadomości.
-
Wyzwania: większy narzut na wydajność, większa złożoność implementacji.
-
Kiedy stosować: systemy finansowe, e-commerce, rezerwacje – tam, gdzie liczy się precyzja.
- Wymaga commitowania po przetworzeniu + Kafka Transactions + idempotentnego producenta.
Zarządzanie offsetami – strategie commitowania
Kafka śledzi, które wiadomości zostały przetworzone, używając offsetów. Commitowanie offsetów pozwala uniknąć powtórnego przetwarzania lub utraty wiadomości w razie awarii. Można to robić na trzy sposoby:
1. Automatyczne commitowanie (enable.auto.commit=true)
Najszybsze, ale najmniej bezpieczne.
-
Jak działa: Kafka commit’uje offsety automatycznie co określony czas.
-
Zalety: Konsument nie musi się niczym przejmować.
-
Wady: Możliwa utrata wiadomości – offset zatwierdzany przed przetworzeniem.
-
Odpowiada modelowi: At most once
-
Kiedy używać: Stateless aplikacje, logowanie, szybkie przetwarzanie bez konsekwencji.
2. Ręczne commitowanie (commitSync(), commitAsync())
Większa kontrola – większe bezpieczeństwo.
-
Jak działa: Konsument sam decyduje, kiedy zatwierdzić offset (najczęściej po przetworzeniu wiadomości).
-
commitSync()– czeka na potwierdzenie → pewniejsze, ale wolniejsze. -
commitAsync()– szybsze, ale offset może zostać utracony w razie awarii.
-
-
Wady: Możliwe duplikaty → potrzebna idempotencja.
-
Odpowiada modelowi: At least once
-
Kiedy używać: Gdy ważne jest, by nie stracić żadnej wiadomości – np. przetwarzanie transakcji.
3. Commitowanie po przetworzeniu wiadomości + transakcje Kafka
Najbezpieczniejsze podejście.
-
Jak działa: Offsety commitowane są dopiero po sukcesie operacji biznesowej. Dodatkowo można użyć transakcji Kafka.
-
Wady: Większy narzut i złożoność implementacyjna.
-
Odpowiada modelowi: Exactly once
-
Kiedy używać: W krytycznych systemach, gdzie nie wolno przetworzyć wiadomości ani dwa razy, ani jej utracić.
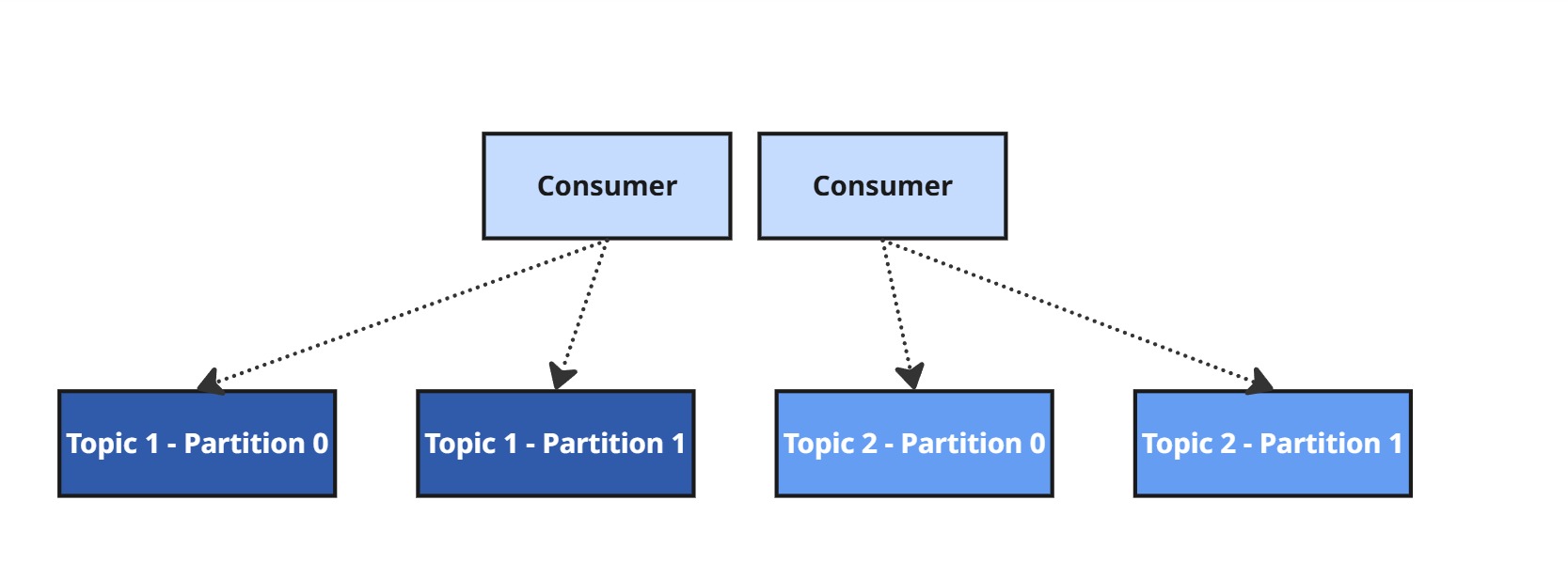
5.2. Grupy konsumenckie i przypisania partycji
Aby skalować przetwarzanie danych i zapewnić równoległość, Kafka umożliwia tworzenie Consumer Groups – grup konsumentów współpracujących ze sobą.
Jak to działa?
Każda partycja jest przypisana do dokładnie jednego konsumenta w danej grupie.
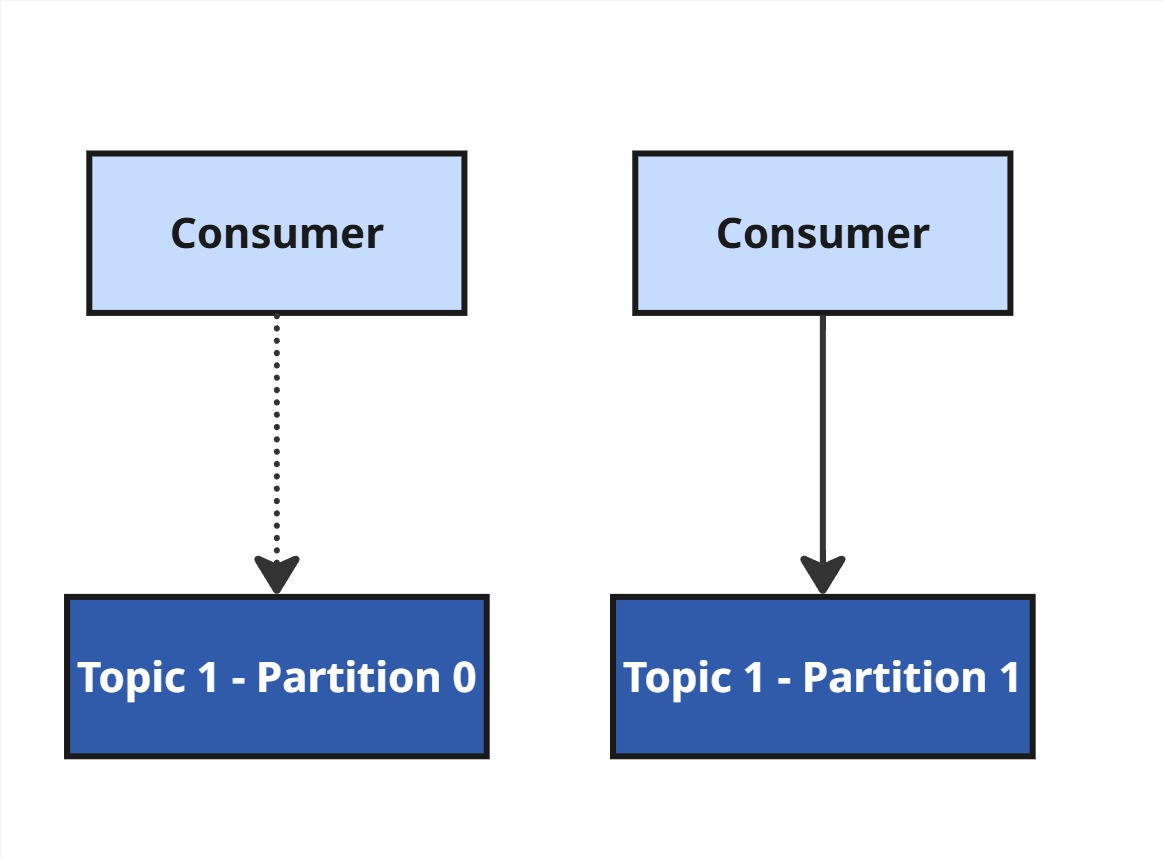
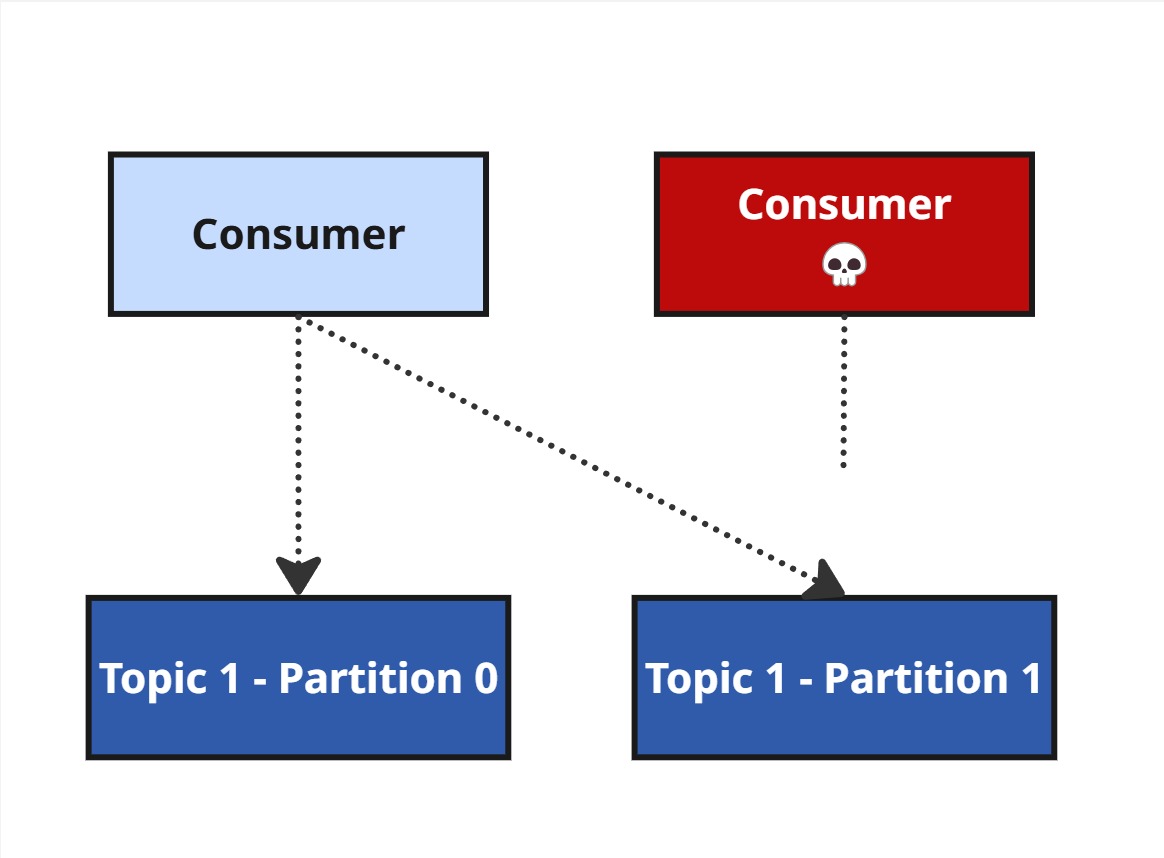
Jeśli konsument padnie, Kafka uruchamia rebalansowanie, by przekazać jego partycje innym.
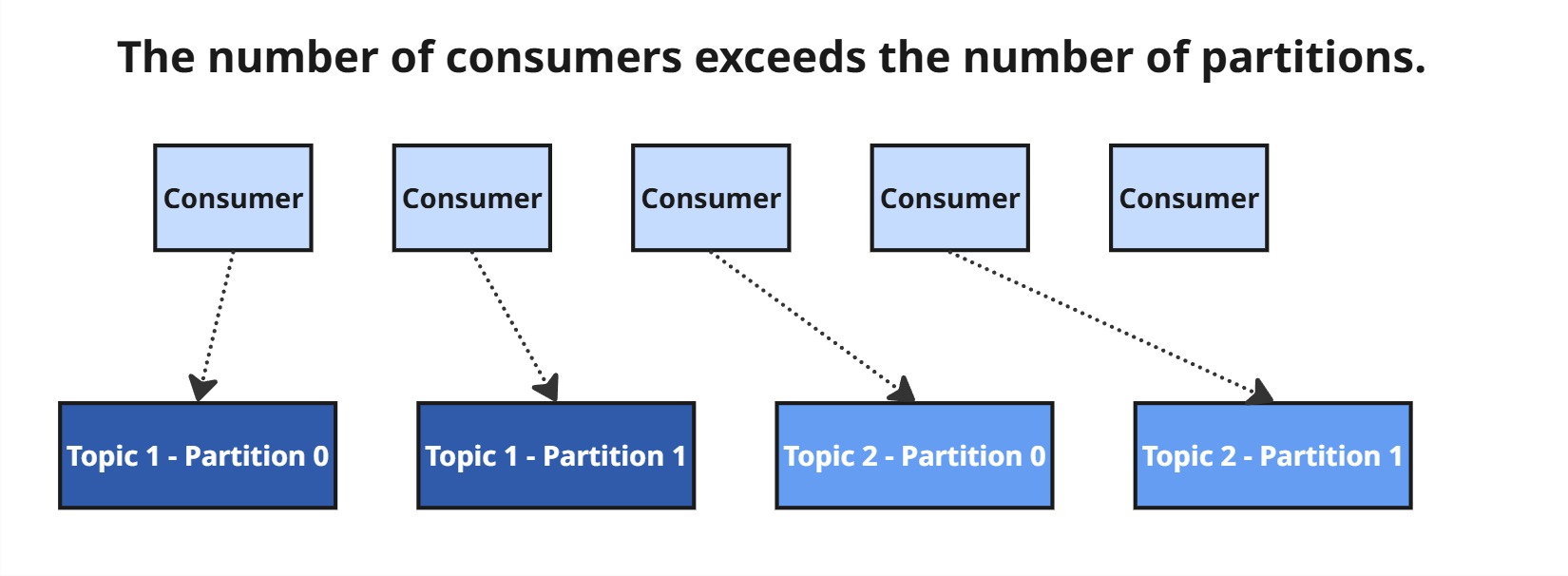
Jeśli konsumentów jest więcej niż partycji, niektórzy pozostaną nieaktywni.
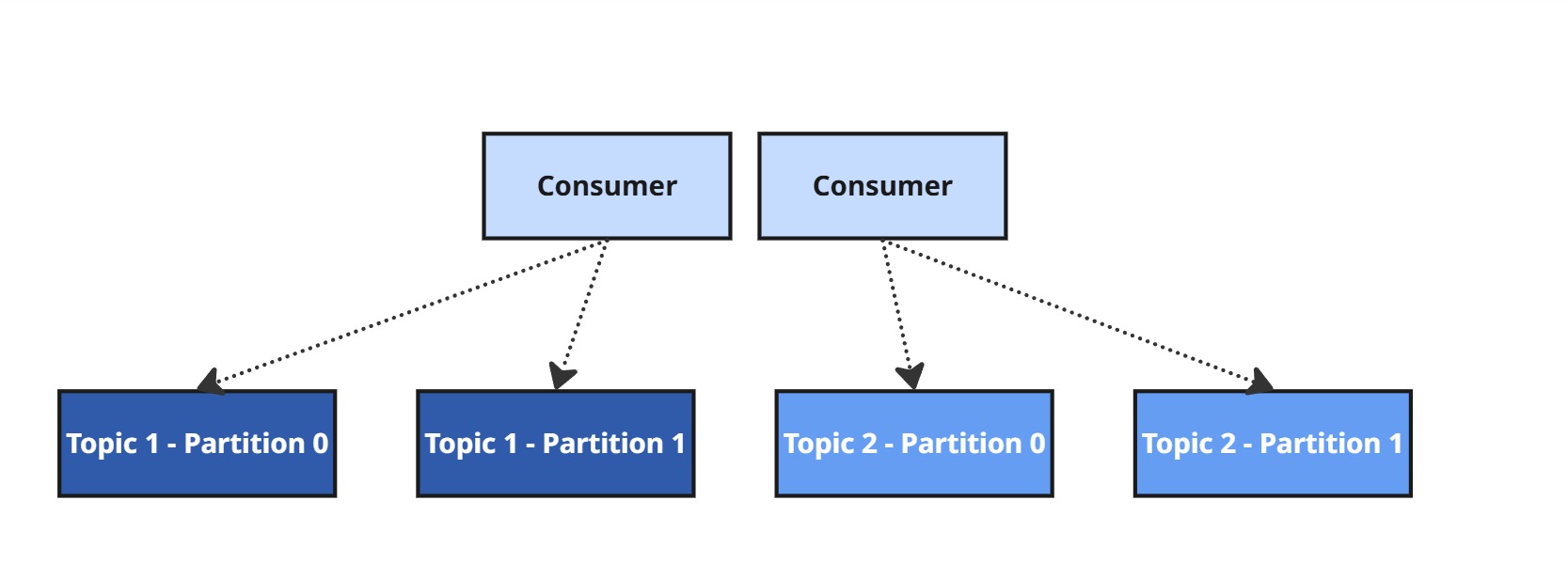
Jeśli konsumentów jest mniej niż partycji, niektórzy będą przetwarzać więcej niż jedną partycję.
5.3. Rodzaje rebalansowania
Rebalansowanie to mechanizm, w ramach którego Kafka dynamicznie przypisuje partycje do konsumentów w grupie. Jest to kluczowy element zapewniający skalowalność, odporność na awarie i równoważenie obciążenia. Jednak może również wprowadzać pewne opóźnienia i skutkować ponownym przetwarzaniem wiadomości.
Cooperative Rebalancing (Współpracujące rebalansowanie) [Rekomendowane]
⚙️ Jak to działa:
Partycje są przekazywane i przejmowane stopniowo – bez konieczności jednoczesnego zwalniania wszystkich przypisań. Konsumenci współpracują, dzięki czemu zmiany są minimalne i rozproszone w czasie.
Wyzwania:
-
Wymaga wsparcia po stronie klienta Kafka (niedostępne w starszych wersjach bibliotek).
-
W niektórych przypadkach może być wolniejsze niż agresywne podejścia.
Kiedy stosować:
-
Gdy zależy Ci na ciągłości przetwarzania i minimalnej latencji.
-
Idealne dla dużych systemów streamingowych, gdzie nawet chwilowa przerwa może oznaczać realne straty biznesowe.
Eager Rebalancing (Agresywne rebalansowanie) [Przestarzałe]
Jak to działa:
Wszystkie partycje są natychmiast zwalniane i przypisywane od nowa. Każdy konsument musi ponownie pobrać offsety i wznowić przetwarzanie.
Wyzwania:
-
Znaczne opóźnienia – każdy rebalance to chwilowy przestój.
-
Potencjalne ponowne przetworzenie wiadomości (jeśli offset nie został jeszcze zatwierdzony).
Kiedy stosować:
-
Tylko jeśli nie możesz użyć Cooperative Rebalancing (np. ze względu na wersję klienta).
-
Gdy liczba konsumentów często się zmienia, a przerwy w przetwarzaniu są akceptowalne.
Sticky Rebalancing (Lepkie rebalansowanie)
Jak to działa:
Kafka stara się utrzymać istniejące przypisania partycji i zmienia je tylko wtedy, gdy to absolutnie konieczne. Minimalizuje tym samym zakres zmian.
Wyzwania:
-
Może prowadzić do nierównomiernego podziału obciążenia – nie gwarantuje idealnie sprawiedliwej dystrybucji.
Kiedy stosować:
-
Gdy nie można użyć Cooperative Rebalancing.
-
W środowiskach z dynamicznie zmieniającą się liczbą konsumentów, gdzie ważniejsza jest stabilność niż idealna równowaga.
6. Kafka Broker
Kafka broker to serwer, który przechowuje i obsługuje partycje topików w ramach klastra Kafka. Klaster Kafki składa się z wielu brokerów, które wspólnie zapewniają wysoką dostępność, równoważenie obciążenia i odporność na awarie.
Kluczowe informacje o brokerach:
-
- Broker to serwer Kafki, który zarządza przechowywaniem i obsługą wiadomości.
- Klaster Kafka składa się z wielu brokerów, co pozwala na skalowanie i niezawodność.
- Każdy broker posiada unikalne ID (integer), które służy do identyfikacji w klastrze.
- Broker przechowuje partycje topików i zarządza ich replikacją.
- Po połączeniu do jednego brokera (tzw. bootstrap broker), klient Kafki automatycznie uzyskuje dostęp do całego klastra. Kafka klient posiada inteligentne mechanizmy do zarządzania połączeniami.
- Minimalna rekomendowana liczba brokerów w klastrze to 3, co zapewnia lepszą odporność na awarie i możliwość replikacji.
6.1. Broker i topiki:
Topic w Kafce może być rozproszony na wiele brokerów poprzez podział na partycje, które są rozdzielane między brokerów.
Przykład:
Załóżmy, że mamy dwa topiki:
-
Topic 1z 3 partycjami (P0,P1,P2) -
Topic 2z 2 partycjami (P0,P1)
A także klaster składający się z 3 brokerów (Broker 1, Broker 2, Broker 3). Partycje mogą zostać rozdzielone między brokerów w sposób zbliżony do:
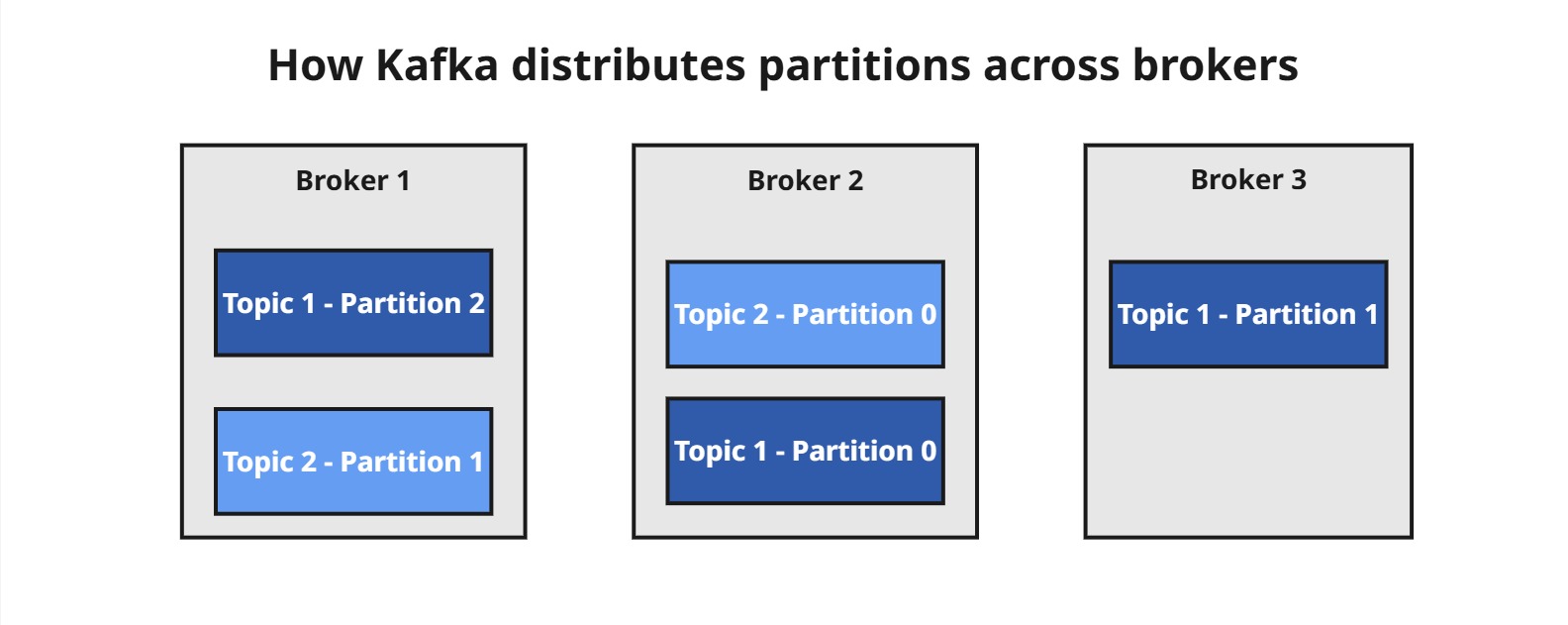
Co nam to daje?
-
Równomierne rozłożenie obciążenia – każdy broker obsługuje inną część danych.
-
Skalowalność pozioma – im więcej brokerów dodasz, tym większa możliwość dystrybucji danych i przetwarzania równoległego.
-
Odporność na awarie – dane są przechowywane na wielu węzłach i mogą być replikowane.
Kafka została zaprojektowana tak, aby naturalnie skalować się wraz z liczbą brokerów, dzięki czemu może obsługiwać zarówno małe systemy, jak i ogromne strumienie danych w czasie rzeczywistym.
6.2. Kafka Broker Discovery – jak klienci znajdują brokerów?
Każdy broker w klastrze pełni rolę bootstrap serwera , co oznacza, że połączenie z dowolnym brokerem umożliwia klientowi uzyskanie informacji o całym klastrze.
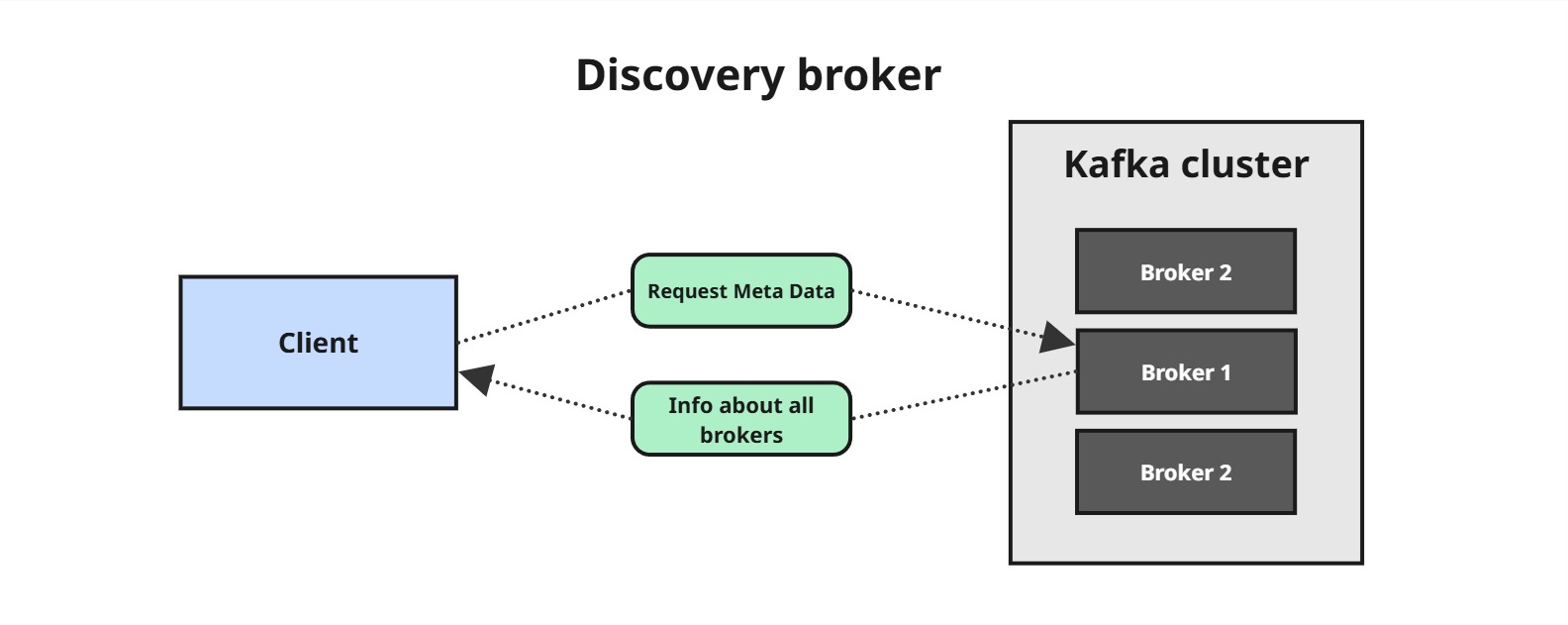
⚙️ Jak to działa?
-
- Połączenie do jednego brokera wystarcza, aby uzyskać listę wszystkich brokerów w klastrze.
- Każdy broker przechowuje metadane dotyczące całego klastra, w tym informacje o dostępnych brokerach, topikach i partycjach.
- W przypadku dodania nowych brokerów lub zmian w partycjach, klient Kafki może dynamicznie aktualizować swoją wiedzę o klastrze.
Dzięki temu Kafka jest odporna na awarie pojedynczych brokerów – jeśli jeden z nich przestanie działać, klient Kafki nadal będzie w stanie połączyć się do klastra za pośrednictwem innych brokerów.
7. Replikacja partycji
Aby zapewnić niezawodność i dostępność danych, Kafka wspiera replikację partycji. Oznacza to, że każda partycja może mieć wiele kopii rozproszonych na różnych brokerach.
Najważniejsze cechy replikacji:
- Jedna replika jest liderem (leader) – tylko ona przyjmuje zapisy i odczyty.
- Pozostałe repliki to followers – pasywnie kopiują dane od lidera.
- Kafka automatycznie wybiera nowego lidera, jeśli dotychczasowy broker-leader przestanie działać.
- Replikacja nie dotyczy całych topików, tylko pojedynczych partycji.
Przykład:
Jeśli masz 2 topiki Topic 1 oraz Topic 2 po jednej partycji i replication.factor=2, to:
-
Kafka zapisze partycje 0 dla każdego topiku na dwóch różnych brokerach.
-
Jeden z nich zostanie leaderem, pozostałe będą kopiować dane.
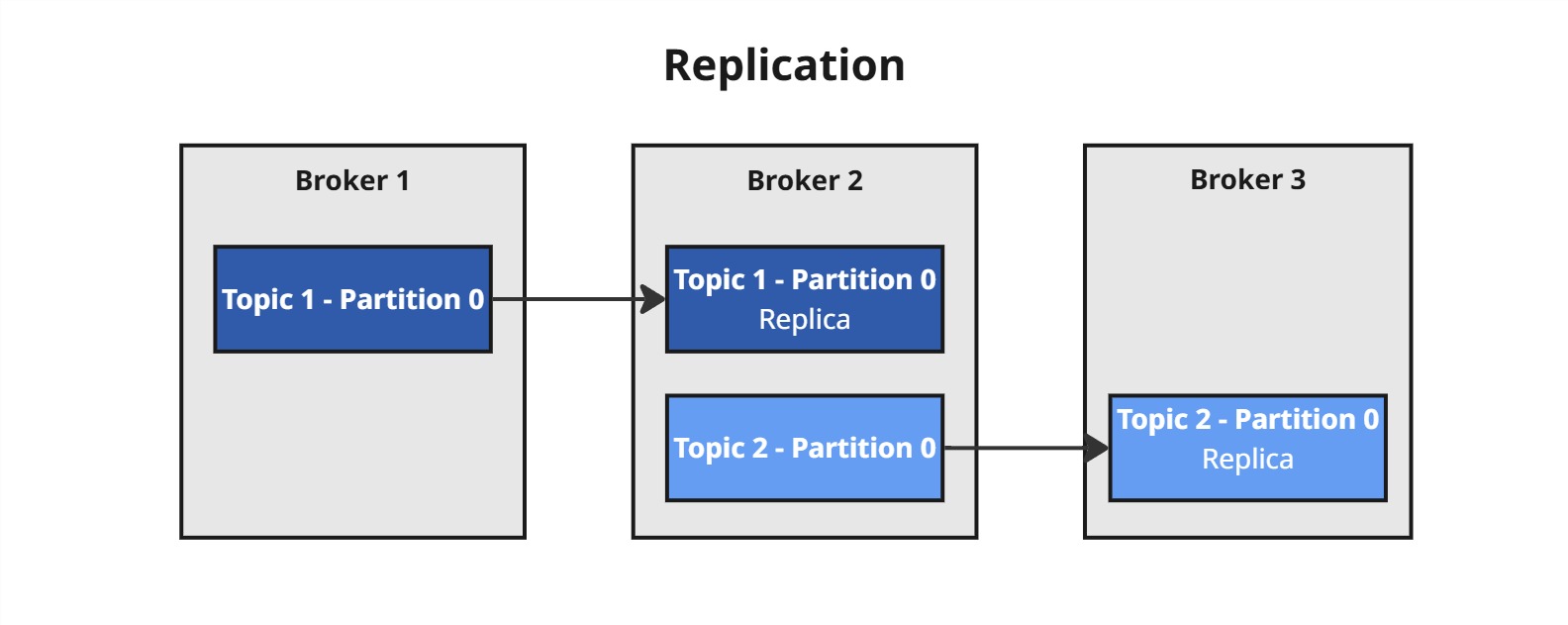
Dzięki temu nawet jeśli jeden (lub więcej) brokerów padnie, dane nie zginą – konsument i producent mogą nadal działać.
Uwaga: replication.factor nie może być większy niż liczba brokerów w klastrze. Przy replication.factor=2 musisz mieć co najmniej 2 brokery.
8. Producer Acknowledgements – kontrola niezawodności zapisu
Podczas wysyłania wiadomości producent może zdecydować, jakiej liczby potwierdzeń zapisu oczekuje od Kafki, ustawiając parametr acks. Wybór tej wartości wpływa na niezawodność i trwałość zapisu danych.
-
acks=0– Producent nie czeka na żadne potwierdzenie. Nie ma gwarancji, że wiadomość dotarła do Kafki – może zostać utracona, jeśli broker padnie tuż po jej otrzymaniu. -
acks=1– Kafka potwierdza odbiór wiadomości, gdy leader partycji zapisze ją lokalnie. Pozostałe repliki (followers) nie muszą jej jeszcze posiadać. Jeśli leader ulegnie awarii przed synchronizacją z replikami, wiadomość może zniknąć. -
acks=all(lubacks=-1) – Potwierdzenie jest wysyłane producentowi dopiero wtedy, gdy wszystkie aktualne repliki, które są w stanie „in-sync” (ISR) zapiszą wiadomość. To zapewnia trwałość zapisu nawet w przypadku awarii lidera, o ile pozostałe repliki są zsynchronizowane.
W połączeniu z odpowiednią replikacją (replication.factor) oraz parametrem min.insync.replicas, Kafka może zapewnić, że topik będzie trwale dostępny nawet w przypadku awarii N-1 brokerów (czyli np. gdy mamy 3 repliki, a 2 brokery ulegną awarii – dane są nadal dostępne na 1 pozostałym brokerze, który był częścią ISR w momencie zapisu).
Ostateczna gwarancja trwałości (durability) zależy więc nie tylko od acks, ale również od tego, ile replik jest zsynchronizowanych w danym momencie, oraz jak skonfigurowano parametry klastra.
Kafka jest narzędziem często wykorzystywanym w przetwarzaniu danych. Mechanizmy przypisywania wiadomości do partycji są kluczowe dla niezawodności systemu. Ręczne przypisywanie kluczy zapewnia kontrolę nad dystrybucją danych. Czy warto rozważyć inne metody przypisywania wiadomości do partycji?